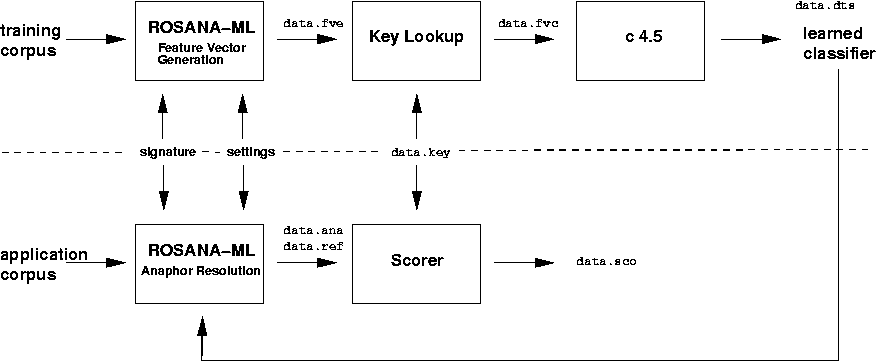
ROSANA-ML
ROSANA-ML is a system for the resolution of anaphors in natural language text based on machine-learned decision trees. The acronym ROSANA-ML stands for robust syntax-based anaphor interpretation employing machine-learned decision trees At current, the system focuses on the resolution of third person non-possessive and possessive pronouns. In implementing and evaluating ROSANA-ML, it is investigated what may be gained by employing machine-learned preference strategies as part of a robust anaphor resolution approach according to the Lappin & Leass (1994) paradigm in which the antecedent filtering strategies are manually designed. The manually crafted algorithm ROSANA is taken as the starting point. Empirical …