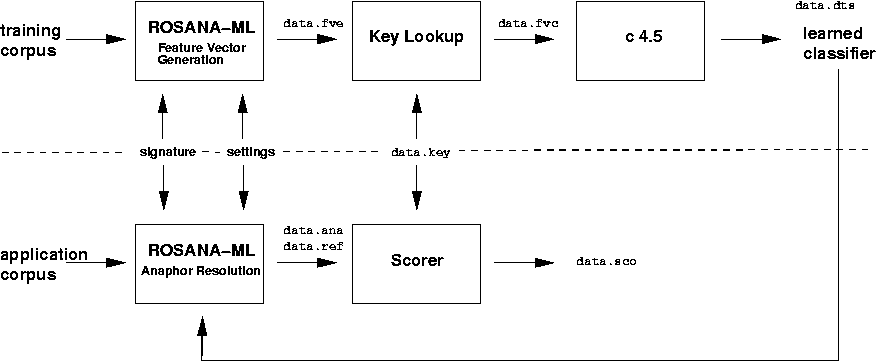
In the figure displayed below, the machine learning approach to anaphor resolution followed by ROSANA-ML is outlined. It is distinguished between the training phase, which is shown in the upper part of the figure, and the application (anaphor resolution) phase sketched in the lower part of the figure.
Training Phase
During the training phase, based on a training text corpus, a set of feature vectors is generated which consists of feature tuples derived from the (anaphor, antecedent candidate) pairs that are considered during the antecedent selection phase of the anaphor resolution algorithm ROSANA. This output is written to a file data.fve, which, during the next step, is classified by employing intellectually gathered key data (file data.key). The result consists of a set of training vectors (file data.fvc) which are classified as either COSPEC or NON_COSPEC, depending on whether, according to the key, the respective occurrences of anaphor and antecedent candidate are cospecifying or not cospecifying. Finally, these training cases are submitted to the C4.5 machine learning algorithm: C4.5 derives a decision-tree-shaped classifier (file data.dts) suitable for categorizing arbitrary feature vectors that are of the same signature as the training vectors.
Application (Anaphor Resolution) Phase
In the application (anaphor resolution) phase, the learned classifiers are employed for antecedent selection: to discern between more and less plausible candidates, instead of applying a set of salience factors (as done by the manually designed algorithm ROSANA), a decision tree lookup is performed, which yields a (heuristic) prediction COSPEC or NON_COSPEC. In combination with a secondary preference criterion (such as surface distance), this prediction renders possible an ordering of the antecedent candidates of an anaphor according to decreasing plausibility. The anaphor resolution output is written to the files data.ana (coreference classes) and data.ref (basically, anaphoric resumption chains). During formal evaluation, the interpretation quality of ROSANA-ML will be measured with respect to various evaluation disciplines, among which are immediate antecedency (ia) and non-pronominal anchors (na) (see below).
For being compatible with the classifiers learned during the training phase, the application version of ROSANA-ML has to employ the identical feature vector signature, i.e. the same Cartesian product of attribute sets to which the individual instances of anaphors and antecedent candidates are mapped. There are further settings, such as the exact way how the antecedent filtering criteria are to be applied, which should be identical during training set generation and application phase (see below).